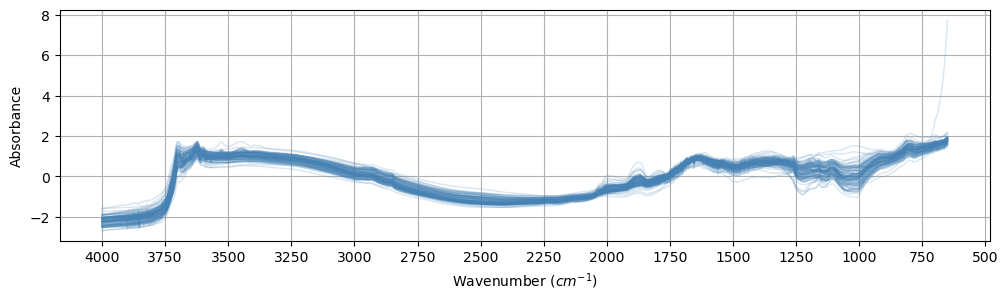
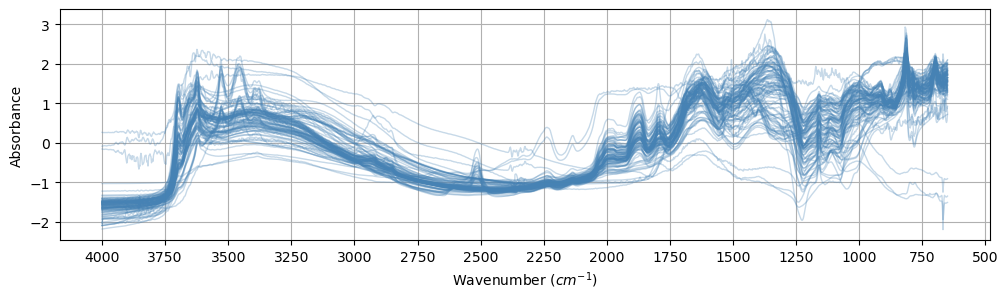
class OSSLLoader(DataLoader):"Load OSSL data and filter it by spectra type and analytes of interest." = {'id.layer_local_c' : 'object' ,'id.location_olc_txt' : 'object' ,'id.dataset.site_ascii_txt' : 'object' ,'id.scan_local_c' : 'object' ,'layer.texture_usda_txt' : 'object' ,'pedon.taxa_usda_txt' : 'object' ,'horizon.designation_usda_txt' : 'object' ,'location.country_iso.3166_txt' : 'object' ,'surveyor.address_utf8_txt' : 'object' ,'efferv_usda.a479_class' : 'object' ,'scan.mir.date.begin_iso.8601_yyyy.mm.dd' : 'object' ,'scan.mir.date.end_iso.8601_yyyy.mm.dd' : 'object' ,'scan.mir.model.name_utf8_txt' : 'object' ,'scan.mir.model.code_any_txt' : 'object' ,'scan.mir.method.optics_any_txt' : 'object' ,'scan.mir.method.preparation_any_txt' : 'object' ,'scan.mir.license.title_ascii_txt' : 'object' ,'scan.mir.license.address_idn_url' : 'object' ,'scan.mir.doi_idf_url' : 'object' ,'scan.mir.contact.name_utf8_txt' : 'object' ,'scan.mir.contact.email_ietf_txt' : 'object' ,'scan.visnir.date.begin_iso.8601_yyyy.mm.dd' : 'object' ,'scan.visnir.date.end_iso.8601_yyyy.mm.dd' : 'object' ,'scan.visnir.model.name_utf8_txt' : 'object' ,'scan.visnir.model.code_any_txt' : 'object' ,'scan.visnir.method.optics_any_txt' : 'object' ,'scan.visnir.method.preparation_any_txt' : 'object' ,'scan.visnir.license.title_ascii_txt' : 'object' ,'scan.visnir.license.address_idn_url' : 'object' ,'scan.visnir.doi_idf_url' : 'object' ,'scan.visnir.contact.name_utf8_txt' : 'object' ,'scan.visnir.contact.email_ietf_txt' : 'object' def __init__ (self , = Path.home() / '.lssm/data/ossl/ossl_all_L0_v1.2.csv.gz' , # Data source file name str = 'visnir' , # Spectra type dict = None ): # Spectra type configuration self .src = srcself .spectra_type = spectra_typeself .df = None self .ds_name_encoder = LabelEncoder()self .cfgs = cfgs or {'visnir' : {'ref_col' : 'scan_visnir.1500_ref' , 'range' : [400 , 2500 ]},'mir' : {'ref_col' : 'scan_mir.1500_abs' , 'range' : [650 , 4000 ]}def _get_spectra(self , str # Spectra type = [name for name in self .df.columns if f'scan_ { spectra_type} .' in name]= self .df[cols_ref].values= self ._get_wavelengths(spectra_type)= self .cfgs[spectra_type]['range' ]= np.where((X_names >= lower_limit) & (X_names <= upper_limit))[0 ]return X[:, idxs], X_names[idxs]def _encode_dataset_names(self ):return self .ds_name_encoder.fit_transform(self .df['dataset.code_ascii_txt' ])def _get_wavelengths(self , str # Spectra type = r"scan_ {} \.(\d+)_" .format (spectra_type)return np.array([int (re.search(pattern, name).group(1 )) for name in self .df.columnsif re.search(pattern, name)])def load_data(self , str | list , # Analyte(s) of interest -> tuple : # Return a tuple of the form (X, y, X_names, smp_idx, ds_name, ds_label) "Load OSSL data and filter it by spectra type and analytes of interest." print (f'Loading data from { self . src} ...' )self .df = pd.read_csv(self .src, dtype= self .DTYPE_DICT,= 'infer' , low_memory= True )= [analytes] if isinstance (analytes, str ) else analytes= np.array(analytes)= analytes + [self .cfgs[self .spectra_type]['ref_col' ]]self .df = self .df.dropna(subset= subset, how= 'any' )= self ._get_spectra(self .spectra_type)= self .df[analytes].values= self .df['id.layer_uuid_txt' ].values= self ._encode_dataset_names()return SpectralData(= X,= X_names,= y,= y_names,= smp_indices,= ds_name,= self .ds_name_encoder.classes_# return X, y, X_names, smp_idx, ds_name, self.ds_name_encoder.classes_, np.array(analytes)