Scale up evaluation report mapping against evaluation frameworks using agentic workflows
Warning
This notebook is a work in progress.
Manually mapping evaluation reports against IOM’s Strategic Results Framework (SRF) is time-consuming and resource-intensive with ~150 outputs to analyze. Additionally, the mapping process needs transparent and human-readable traces of LLM decision flows that both reflect natural reasoning patterns and allow human evaluators to audit the mapping logic.
Read evaluation report from enriched markdown pages
Type
Details
doc_path
str
Path to the evaluation report
Exported source
def load_report( doc_path:str# Path to the evaluation report ):"Read evaluation report from enriched markdown pages" doc = Path(doc_path) pages = doc.ls(file_exts=".md").sorted(key=lambda p: int(p.stem.split('_')[1])) report ='\n\n---\n\n'.join(page.read_text() for page in pages)return report
# "abridged_evaluation_report_final_olta_ndoja_pdf/enriched" (shorter version for testing)doc_path ="../_data/md_library/49d2fba781b6a7c0d94577479636ee6f/final_evaluation_report_final_olta_ndoja_pdf/enriched"doc_path ="../_data/md_library/evaluation-of-iom-accountability-tmp/aap_evaluation_report_final_pdf/enriched"doc_path ="../_data/md_library/evaluation-of-iom-accountability-tmp/final_evaluation_report_final_pdf/enriched"doc_path ="../_data/md_library/22cac1c000836253adc445993e101560/final_report_evaluation_of_mhpss_in_iom_8_2024_pdf/enriched"report = load_report(doc_path)print(report[:1000])
!(img-0.jpeg)
# Evaluation of Mental Health and Psychosocial Support in IOM .... page 1
IOM CENTRAL EVALUATION
August 2024
---
# ACKNOWLEDGEMENTS .... page 2
The evaluation was undertaken by external consultants of Peace in Practice consultancy, on behalf of the Central
Evaluation Division (CED). The team was composed of Dr. Leslie Snider (lead) and Dr. Carolina Herbert.
The consultants would like to extend their sincere thanks to all those who gave their time and input to the
evaluation, including the representatives of Member States, UN agencies, international NGOs, academia and other
external stakeholders, and IOM staff and managers at all levels of the Organization. Special appreciation is
extended to IOM MHPSS staff and managers for their thoughtful reflections, and to the contributors for the case
studies from IOM MHPSS country and regional offices in Ukraine, Poland, West and Central Africa, and Colombia.
Finally, the consultants are grateful for the unwaverin
Hierarchical report navigation
Thanks to toolslm.md_hier and a clean markdown structure of a report markdown, we can create a nested dictionary of section, subsection, … as follows:
Find the nested key path for a given section name.
Type
Details
hdgs
dict
The nested dictionary structure
target_section
str
The section name to find
Returns
list
The nested key path for the given section name
Exported source
def find_section_path( hdgs: dict, # The nested dictionary structure target_section: str# The section name to find) ->list: # The nested key path for the given section name"Find the nested key path for a given section name."def search_recursive(current_dict, path=[]):for key, value in current_dict.items(): current_path = path + [key]if key == target_section:return current_pathifisinstance(value, dict): result = search_recursive(value, current_path)if result:return resultreturnNonereturn search_recursive(hdgs)
Then we can retrieve the subsection path (list of nested headings to reach this specific section) in this nested hdgs dict :
Navigate through nested levels using the exact key strings.
Type
Details
hdgs
dict
The nested dictionary structure
keys_list
list
The list of keys to navigate through
Returns
str
The content of the section
Exported source
def get_content_tool( hdgs: dict, # The nested dictionary structure keys_list: list, # The list of keys to navigate through ) ->str: # The content of the section"Navigate through nested levels using the exact key strings."returnreduce(lambda current, key: current[key], keys_list, hdgs).text
---------------------------------------------------------------------------TypeError Traceback (most recent call last)
CellIn[98], line 2 1#| eval: false----> 2 content = get_content_tool(hdgs,path) 3print(content[:500])
CellIn[97], line 7, in get_content_tool(hdgs, keys_list) 2defget_content_tool(
3 hdgs: dict, # The nested dictionary structure 4 keys_list: list, # The list of keys to navigate through 5 ) -> str: # The content of the section 6"Navigate through nested levels using the exact key strings."----> 7returnreduce(lambdacurrent,key:current[key],keys_list,hdgs).text
TypeError: reduce() arg 2 must support iteration
Extract flat list of (key, full_path) tuples from nested hdgs
Type
Default
Details
hdgs
dict
The nested dictionary-like structure of the report also allowing to pull content from
path
list
[]
The current path in the nested structure
Returns
list
The flat list of (key, full_path) tuples
Exported source
def flatten_sections( hdgs: dict, # The nested dictionary-like structure of the report also allowing to pull content from path: list= [] # The current path in the nested structure ) ->list: # The flat list of (key, full_path) tuples"Extract flat list of (key, full_path) tuples from nested hdgs" sections = []for key, value in hdgs.items(): current_path = path + [key] sections.append((key, current_path))ifisinstance(value, dict): sections.extend(flatten_sections(value, current_path))return sections
print(flatten_sections(hdgs)[:10])
[('Evaluation of IOM Accountability to Affected Populations',
['Evaluation of IOM Accountability to Affected Populations']),
('IOM CENTRAL EVALUATION',
['Evaluation of IOM Accountability to Affected Populations', 'IOM CENTRAL EVALUATION']),
('December 2024',
['Evaluation of IOM Accountability to Affected Populations', 'IOM CENTRAL EVALUATION', 'December 2024']),
('ACKNOWLEDGEMENTS', ['ACKNOWLEDGEMENTS']),
('TABLE OF CONTENTS', ['TABLE OF CONTENTS']),
('LIST OF FIGURES AND TABLES', ['LIST OF FIGURES AND TABLES']),
('LIST OF ACRONYMS', ['LIST OF ACRONYMS']),
('EXECUTIVE SUMMARY', ['EXECUTIVE SUMMARY']),
('1. BACKGROUND', ['1. BACKGROUND']),
('Evaluation Context', ['1. BACKGROUND', 'Evaluation Context'])]
def format_toc_for_llm(hdgs: dict) ->str:"""Format ToC as readable text with page numbers""" sections = flatten_sections(hdgs) lines = [f"- {key}"for key, path in sections]return'\n'.join(lines)
print(format_toc_for_llm(hdgs)[:500])
- Evaluation of IOM Accountability to Affected Populations
- IOM CENTRAL EVALUATION
- December 2024
- ACKNOWLEDGEMENTS
- TABLE OF CONTENTS
- LIST OF FIGURES AND TABLES
- LIST OF ACRONYMS
- EXECUTIVE SUMMARY
- 1. BACKGROUND
- Evaluation Context
- Evaluation Purpose, Objectives and Scope
- Methodology
- Data Sources
- Desk Review
- Remote and In-Person Key Informant Interviews
- Focus Group Discussions
- Online Survey
- Case Studies
- Sampling
- Limitations
- Ethical Considerations
- 2. EVALUATION
Formatters
We define here a set of function formatting both evaluation frameworks themes to analyze (SRF enablers, objectives, GCM objectives, …) and traces.
Format SRF enabler into structured text for LM processing.
Type
Details
theme
EvalData
The theme object
Returns
str
The formatted theme string
Exported source
def format_enabler_theme( theme: EvalData # The theme object ) ->str: # The formatted theme string"Format SRF enabler into structured text for LM processing." parts = [f'## Enabler {theme.id}: {theme.title}','### Description', theme.description ]return'\n'.join(parts)
For instance:
eval_data = IOMEvalData()data_evidence = eval_data.srf_enablers[3] # "Data and evidence" is at index 3print(format_enabler_theme(data_evidence))
## Enabler 4: Data and evidence
### Description
IOM will be the pre-eminent source of migration and displacement data for action, which help save lives and deliver
solutions; data for insight, which help facilitate regular migration pathways; and data for foresight, which help
drive anticipatory action. IOM will have the systems and data fluency to collect, safely store, analyze, share and
apply disaggregated data and evidence across the mobility spectrum. Our extensive data and research repositories
will underpin evidence-based policies and practices. Data will be central to the internal decision-making and
management of the Organization.
Format SRF cross-cutting into structured text for LM processing.
Type
Details
theme
EvalData
The theme object
Returns
str
The formatted theme string
Exported source
def format_crosscutting_theme( theme: EvalData # The theme object ) ->str: # The formatted theme string"Format SRF cross-cutting into structured text for LM processing." parts = [f'## Cross-cutting {theme.id}: {theme.title}','### Description', theme.description ]return'\n'.join(parts)
For instance:
eval_data = IOMEvalData()env_sustainability = eval_data.srf_crosscutting_priorities[3] # "Data and evidence" is at index 3print(format_crosscutting_theme(env_sustainability))
## Cross-cutting 4: Environmental Sustainability
### Description
IOM will lead environmental sustainability innovation for impact and scale in the humanitarian and migration
management sector. Caring for people and the planet is one of our core values, and we are committed to
mainstreaming environmental sustainability into our projects and programmes, and facilities management and
operations. IOM will have an ambitious environmental governance and environmental management system drawing from
United Nations system-wide commitments
## GCM Objective 4: Ensure that all migrants have proof of legal identity and adequate documentation
### Core Theme
Strengthen civil registry systems and ensure migrants have necessary identity documents
### Key Principles
Legal identity, Civil registration, Document security, Consular services
### Target Groups
Migrants, Stateless persons, Children, Consular authorities
### Main Activities
Civil registry improvement, Document issuance, Biometric systems, Consular documentation
formatted_objectives = [format_gcm_theme(o) for o in gcm_small]markdown_content ='\n\n'.join(formatted_objectives)output_path ="formatted_gcm_objectives.md"withopen(output_path, "w", encoding="utf-8") as f: f.write(markdown_content)print(f"Dumped {len(formatted_objectives)} GCM objectives to {output_path}")
Dumped 23 GCM objectives to formatted_gcm_objectives.md
## SRF Output 1a11: Crisis-affected populations in-need receive dignified shelter and settlement support.
### Strategic Context
**Objective 1**: Saving lives and protecting people on the move
**Long -term Outcome 1a**: Human suffering is alleviated while the dignity and rights of people affected by
crises are upheld.
**Short-term Outcome 1a1**: Crisis-affected populations have their basic needs met and have minimum living
conditions with reduced barriers to access for marginalized and vulnerable individuals.
class ThemeTaggingOutput(BaseModel):"Tag the theme in the report" is_core: bool reasoning: str evidence_locations: list[EvidenceLocation] confidence: str# low/medium/high
System prompts
Exported source
select_section_sp ="""### ROLE AND OBJECTIVEYou are an expert evaluation report analyst. Your task is to identify sections that would help determine if specific themes are CORE to this report for synthesis and retrieval purposes.### CONTEXTYou will receive a table of contents (ToC) with section headings from an evaluation report. Select sections where report authors signal what matters most - these will be used to tag themes for future synthesis work.### SECTIONS TO IDENTIFYLook for sections that reveal core themes (in any language):1. Executive Summary / Overview / Résumé exécutif / Resumen ejecutivo2. Introduction / Objectives / Purpose / Questions d'évaluation / Preguntas de evaluación3. Main Findings / Results / Résultats / Resultados / Constatations4. Conclusions / Conclusiones5. Recommendations / Recommandations / Recomendaciones### SELECTION CRITERIA- Match flexibly by meaning, not exact wording- Prioritize where authors explicitly state what's important- Aim for ~8-10 pages total (use page numbers in ToC as guide)- Avoid methodology, background, annexes unless unusually central- Not all report types have all sections - select what exists### OUTPUT FORMATJSON with section_names (list) and reasoning (string).**CRITICAL**: section_names must contain EXACT strings from the ToC provided.Copy the complete line including section numbers and page references.Example: If ToC shows "4.1. Relevance of programme activities .... page 34"Return exactly: "4.1. Relevance of programme activities .... page 34""""
Exported source
tagging_sp ="""### ROLE AND OBJECTIVEYou are an evaluation synthesis specialist. Your task is to determine if this report should be tagged with a specific theme for future retrieval in synthesis work.### CONTEXTYou will receive:- Key sections from an evaluation report- A specific theme to evaluate### CRITICAL DISTINCTIONYou are NOT evaluating whether the theme is mentioned or relevant.You ARE evaluating whether the theme is CENTRAL to what this report is fundamentally about.### TAGGING DECISION CRITERIATag as CORE only if the theme meets BOTH conditions:**1. Centrality Test**: The theme is a PRIMARY focus of the report:- The theme appears in the report's main objectives/evaluation questions- Multiple major sections dedicate substantial analysis to this theme- Key findings and conclusions center on this theme- Major recommendations address this theme**2. Synthesis Value Test**: Ask yourself:"If I were synthesizing evaluation findings specifically on [Theme X], would EXCLUDING this report create a significant gap in my synthesis?"### DECISION RULE- Tag as CORE: The report would be among the TOP sources for a synthesis on this theme- Tag as NOT CORE: The report mentions the theme but isn't fundamentally about it**When uncertain → Tag as NOT CORE**Aim for precision: Only 2-4 themes per report should be CORE.### OUTPUT FORMATJSON with:- is_core: boolean- reasoning: explain centrality (or lack thereof) with specific evidence- evidence_locations: list of {"section": "...", "citation": "..."}- confidence: low/medium/high"""
Exported source
tagging_sp_no_citation ="""### ROLE AND OBJECTIVEYou are an evaluation synthesis specialist. Your task is to determine if this report should be tagged with a specific theme for future retrieval in synthesis work.### CONTEXTYou will receive:- Key sections from an evaluation report- A specific theme to evaluate### CRITICAL DISTINCTIONYou are NOT evaluating whether the theme is mentioned or relevant.You ARE evaluating whether the theme is CENTRAL to what this report is fundamentally about.### TAGGING DECISION CRITERIATag as CORE only if the theme meets BOTH conditions:**1. Centrality Test**: The theme is a PRIMARY focus of the report:- The theme appears in the report's main objectives/evaluation questions- Multiple major sections dedicate substantial analysis to this theme- Key findings and conclusions center on this theme- Major recommendations address this theme**2. Synthesis Value Test**: Ask yourself:"If I were synthesizing evaluation findings specifically on [Theme X], would EXCLUDING this report create a significant gap in my synthesis?"### DECISION RULE- Tag as CORE: The report would be among the TOP sources for a synthesis on this theme- Tag as NOT CORE: The report mentions the theme but isn't fundamentally about it**When uncertain → Tag as NOT CORE**Aim for precision: Only 2-4 themes per report should be CORE.### OUTPUT FORMATJSON with:- is_core: boolean- reasoning: explain centrality (or lack thereof) with specific evidence (max 150 words)- confidence: low/medium/high"""
The nested dictionary-like structure of the report also allowing to pull content from
system_prompt
str
The system prompt for the core sections identification
model
str
gemini/gemini-2.0-flash
The model to use
Returns
dict
The JSON response from the model
Exported source
asyncdef identify_core_sections( hdgs: dict, # The nested dictionary-like structure of the report also allowing to pull content from system_prompt: str, # The system prompt for the core sections identification model: str='gemini/gemini-2.0-flash'# The model to use) ->dict: # The JSON response from the model chat = AsyncChat(model=model, sp=system_prompt, temp=0) toc_text = format_toc_for_llm(hdgs) result =await chat(f"Here is the table of contents:\n\n{toc_text}", response_format=CoreSectionsOutput )return parse_response(result)
{'section_names': ['EXECUTIVE SUMMARY .... page 5',
'Findings .... page 6',
'Conclusions .... page 6',
'Recommendations .... page 8',
'1. OBJECTIVE, SCOPE AND METHODOLOGY OF THE EVALUATION .... page 9',
'Objective of the Evaluation .... page 9',
'3. MAIN EVALUATION FINDINGS .... page 18',
'4. CONCLUSIONS .... page 48',
'5. RECOMMENDATIONS .... page 53'],
'reasoning': 'The selected sections cover the core elements of the evaluation report, including the executive summary, findings, conclusions, and recommendations. The objective and scope section provides context for the evaluation. These sections are most likely to contain the key themes and insights from the evaluation.'}
# EXECUTIVE SUMMARY .... page 5
The International Organization for Migration (IOM)'s Central Evaluation Division (CED) commissioned this thematic and strategic evaluation of IOM's Mental Health and Psychosocial Support (MHPSS) work as part of the biennial
evaluation plan 2023-2024. MHPSS has become an area of institutional importance to IOM, and the evaluation provided
the opportunity to take stock of IOM's work in MHPSS since the post-2015 development agenda, including internal
synergies, adap
from pathlib import Pathcore_content = extract_core_content(core_sections['section_names'], hdgs)output_path = Path("retrieved_core_sections.md")output_path.write_text(core_content, encoding="utf-8")print(f"Dumped {len(core_sections['section_names'])} core sections to {output_path}")
Dumped 9 core sections to retrieved_core_sections.md
asyncdef tag_theme( doc_content: str, # The content of the document to analyze theme: str, # The theme to tag system_prompt: str, # The system prompt for the theme tagging response_format: type= TagResult, # The response format for the theme tagging model: str="claude-sonnet-4-5", # The model to use cache_system: bool=True, # Always cache system+doc (default) cache_theme: bool=False# Only cache theme for resume):"Tag a single theme against the document" system_blocks = [ {"type": "text", "text": system_prompt}, {"type": "text", "text": f"\n\n## Document to Analyze\n\n{doc_content}"} ]if cache_system: system_blocks[-1]["cache_control"] = {"type": "ephemeral"} messages = [mk_msg(theme, cache=cache_theme)] response =await acompletion( model=model, messages=messages, system=system_blocks, response_format=response_format )return response
ModelResponse(id='chatcmpl-09cff953-caaa-4677-bff5-4039d8a978d6',
created=1762791010,
model='claude-sonnet-4-5-20250929',
object='chat.completion',
system_fingerprint=None,
choices=[Choices(finish_reason='stop',
index=0,
message=Message(content='{"is_core": false, "reasoning": "While the report extensively discusses IOM staff capacity, training, and human resources (particularly in the Efficiency section noting that \\"human resources weremostly sufficient\\" and improvements in \\"allocating additional qualified staff\\"), workforce development is nota primary focus of this evaluation. The report is fundamentally about assessing the EU-IOM Joint Initiative\'s migrant protection, return, and reintegration program outcomes. \\n\\nStaff and workforce considerations appear as operational inputs and implementation factors rather than as central evaluation questions. The main themes are: migrant protection and safe return, reintegration support (economic, social, psychosocial), community-based projects, government capacity building, and program sustainability. \\n\\nWorkforce issues are mentioned instrumentally - how adequate staffing contributed to program delivery - but there are no dedicated sections analyzing workforce planning, staff well-being, leadership development, or organizational culture. The capacity-building discussed focuses on external stakeholders (governments, service providers) rather than internal IOM workforce development. \\n\\nFor a synthesis specifically on IOM workforce development, this report would provide minimal substantive content.", "confidence": "high"}',
role='assistant',
tool_calls=None,
function_call=None,
provider_specific_fields=None))],
usage=Usage(completion_tokens=293,
prompt_tokens=26,
total_tokens=319,
completion_tokens_details=None,
prompt_tokens_details=PromptTokensDetailsWrapper(audio_tokens=None,
cached_tokens=0,
text_tokens=None,
image_tokens=None),
cache_creation_input_tokens=9568,
cache_read_input_tokens=0))
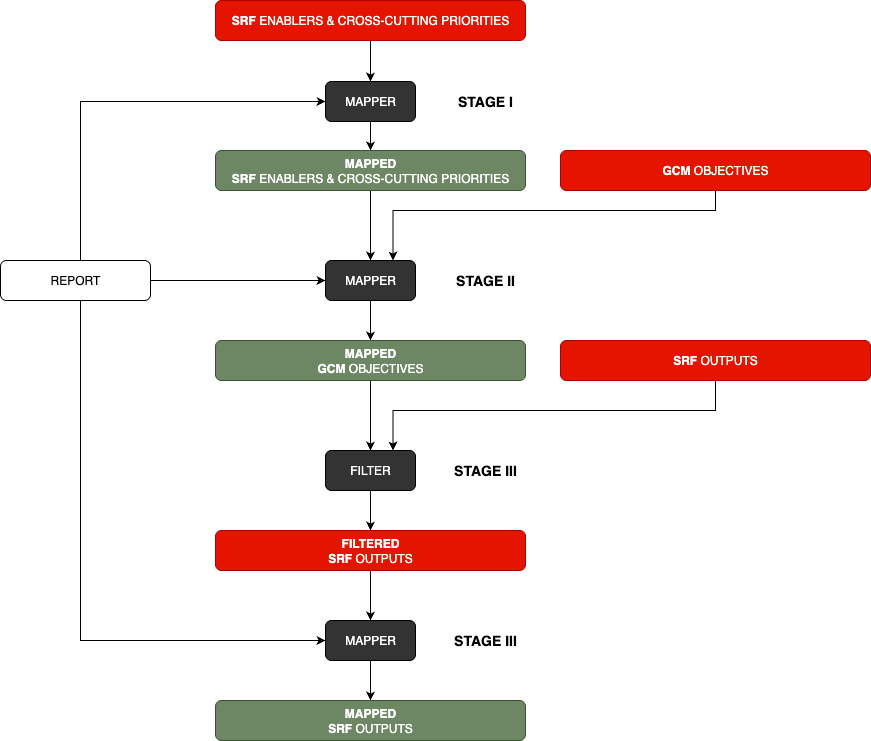
We treat observability and LLM evaluation as core requirements for our mapping pipeline. While DSPy’s built-in dspy.inspect_history() provides valuable reasoning chains, we enhance it with structured metadata (report_id, phase, framework) to create comprehensive audit trails. This enriched tracing enables systematic evaluation of mapping accuracy, supports human evaluator annotation workflows, and provides the detailed context necessary for debugging and improving our LLM-based document analysis system.
We define below enum and configuration classes for pipeline tracing and validation. These provide structured metadata for audit trails and evaluation.
Helper function to setup a logger with common configuration
Type
Default
Details
name
str
The name of the logger
handler
Handler
The handler to use
level
int
20
The level of the logger
kwargs
dict
Exported source
def setup_logger( name: str, # The name of the logger handler: logging.Handler, # The handler to use level: int= logging.INFO, # The level of the logger**kwargs: dict# Additional keyword arguments ):"Helper function to setup a logger with common configuration" logger = logging.getLogger(name) logger.handlers.clear() logger.addHandler(handler) logger.setLevel(level)for k,v in kwargs.items(): setattr(logger, k, v)return logger
Log an analysis event to file and console with different verbosity levels
Type
Default
Details
event
str
The event to log
report_id
str
The report identifier
stage
Stage
None
The stage of the pipeline
framework_info
FrameworkInfo
None
The framework information
extra_data
dict
Exported source
def _build_base_data( event: str, # The event to log report_id: str, # The report identifier stage: Stage =None, # The stage of the pipeline framework_info: FrameworkInfo =None, # The framework information**extra_data: dict# Additional keyword arguments ):"Build base data dictionary for logging" base_data = {"timestamp": datetime.now().isoformat(),"event": event,"report_id": report_id, }if stage: base_data["stage"] =str(stage)if framework_info: base_data.update({"framework": str(framework_info.name),"framework_category": str(framework_info.category),"framework_theme_id": str(framework_info.theme_id), }) base_data.update(extra_data)return base_data
Exported source
def _format_console_msg( base_data: dict, # The base data to format verbosity: int, # The verbosity level stage: Stage, # The stage of the pipeline framework_info: FrameworkInfo # The framework information ):"Format console message based on verbosity level" report_id = base_data['report_id'] event = base_data['event']if verbosity ==1:returnf"{report_id}"+ (f" - {stage}"if stage else"")elif verbosity ==2: parts = [report_id]if stage: parts.append(str(stage)) parts.append(event)if framework_info: parts.append(f"{framework_info.name}/{framework_info.category}/{framework_info.theme_id}")return" - ".join(parts)else: # verbosity == 3return json.dumps(base_data, indent=2)
Exported source
def log_analysis_event( event: str, # The event to log report_id: str, # The report identifier stage: Stage =None, # The stage of the pipeline framework_info: FrameworkInfo =None, # The framework information**extra_data: dict# Additional keyword arguments ):"Log an analysis event to file and console with different verbosity levels" file_logger = logging.getLogger('trace.file') console_logger = logging.getLogger('trace.console') base_data = _build_base_data(event, report_id, stage, framework_info, **extra_data)# File logger - always full JSON file_logger.info(json.dumps(base_data, indent=2))# Console logger - verbosity-basedifhasattr(console_logger, 'verbosity'): console_msg = _format_console_msg(base_data, console_logger.verbosity, stage, framework_info) console_logger.info(console_msg)
Generic cache retrieval, returns None if not found
Type
Details
table
The cache table
pk_value
str
The primary key value
Exported source
def get_from_cache( table, # The cache table pk_value: str# The primary key value ):"Generic cache retrieval, returns None if not found"try:return table.get(pk_value)except NotFoundError:returnNone
def store_in_cache( table, # The cache table data: dict# The data to store ):"Generic cache storage with automatic timestamp" data['timestamp'] = datetime.now().isoformat() table.upsert(data)
Execute coroutine with semaphore concurrency control
Type
Default
Details
semaphore
The semaphore to use
coro
The coroutine to execute
delay
float
None
The delay to wait
Exported source
asyncdef limit( semaphore, # The semaphore to use coro, # The coroutine to execute delay: float=None# The delay to wait ):"Execute coroutine with semaphore concurrency control"asyncwith semaphore: result =await coroif delay: await sleep(delay)return result
class PipelineResults(dict):"The results of the pipeline"def__init__(self):super().__init__()self[Stage.STAGE1] = defaultdict(lambda: defaultdict(dict))self[Stage.STAGE2] = defaultdict(lambda: defaultdict(dict))self[Stage.STAGE3] = defaultdict(lambda: defaultdict(dict))
@patchdef__call__(self:PipelineResults, stage: Stage = Stage.STAGE1, # The stage of the pipeline filter_type: str="all"# The filter type ):"The results of the pipeline" themes = []for frameworks inself[stage].values():for categories in frameworks.values():for theme in categories.values():if filter_type =="all"or\ (filter_type =="tagged"and theme.is_core) or\ (filter_type =="untagged"andnot theme.is_core): themes.append(theme)return themes
class PipelineOrchestrator:"The orchestrator of the pipeline"def__init__(self, report_id: str, # The report identifier hdgs: dict, # The heading dictionary eval_data: EvalData, # The evaluation data cfg: AttrDict # The configuration ):self.cfg_p = cfg.pipeline store_attr() setup_trace_logging(report_id, self.cfg_p.verbosity)self.results = PipelineResults()self.core_sections =Noneself.doc_content =None
import matplotlib.pyplot as pltgcm_ids =list(eval_data.gcm_srf_lut.keys())srf_counts = [len(srf_outputs) for srf_outputs in eval_data.gcm_srf_lut.values()]plt.figure(figsize=(8, 3))plt.bar(gcm_ids, srf_counts, color='steelblue')plt.xlabel('GCM Objective')plt.ylabel('Number of SRF Outputs')plt.title('Number of SRF Outputs per GCM Objective')plt.xticks(rotation=45)plt.tight_layout()plt.show()
### Report Preliminary Context
This evaluation report covers the following Strategic Results Framework themes:
- **Enablers 2**: Partnership
- **Enablers 4**: Data and evidence
- **Enablers 5**: Learning and Innovation
- **Crosscutting Priorities 3**: Protection-centred
### Covered GCM Objectives
- **GCM 1**: Collect and utilize accurate and disaggregated data as a basis for evidence-based policies
- **GCM 7**: Address and reduce vulnerabilities in migration
- **GCM 12**: Strengthen certainty and predictability in migration procedures for appropriate screening, assessment
and referral
- **GCM 16**: Empower migrants and societies to realize full inclusion and social cohesion
- **GCM 21**: Cooperate in facilitating safe and dignified return and readmission, as well as sustainable
reintegration
- **GCM 23**: Strengthen international cooperation and global partnerships for safe, orderly and regular migration