SVD Through Variational Principles: From Geometry to the Classical Formulation
Understanding what matrices do to space, and how SVD emerges from finding maximally coupled directions
Linear Algebra
LLMs
Kernel Methods
Sustainable AI
Primal Attention
Author
Franck Albinet
Published
January 20, 2026
Part 1 of 4 · Primal Attention Series
As AI scales, so does its energy footprint. Johan Suykens, creator of Least Squares Support Vector Machines (LS-SVM), has spent decades exploring how kernel methods can yield elegant, compact solutions. His 2016 paper “SVD revisited” reformulates SVD through a variational principle that reveals deep structure. A structure that connects directly to attention mechanisms in transformers. The 2023 Primal-Attention paper follows this thread, showing how kernel SVD enables equivalent performance with far more compact networks. This isn’t optimization for its own sake; it’s a path toward sustainable AI.
These papers are technically demanding and assume significant background. My goal is to smooth the learning curve, to reveal the beauty and insight of this framework, and why it matters for the future of AI.
This is a four-part series:
Part 1 (this post): Rebuild SVD from geometry to its classical variational formulation
Part 2: A detour through PCA to understand the LS-SVM mindset: competing forces, equilibrium, and beautiful geometry
Part 3: Suykens’ LS-SVM reformulation of SVD and kernelization (covering “SVD revisited”)
Part 4: From kernel SVD to attention mechanisms (covering “Primal-Attention”)
We start by asking: what does a matrix do to space? Most ML engineers know SVD as u, s, v = torch.linalg.svd(A), but the geometric intuition fades. For square matrices, eigenvalues answer this. For rectangular matrices, they can’t. So we exhibit the four fundamental subspaces, revealing that singular vectors are maximally coupled through the matrix. We then show how the classical variational formulation, a different perspective, arrives at the same solution.
Our audience: ML/AI practitioners who want geometric intuition alongside rigor. Proofs where they illuminate, code where it grounds abstraction.
From Eigenvalues to SVD
What does a matrix actually do? This question drives everything that follows. In machine learning, matrices aren’t abstract objects, they encode data (m samples as rows, n features as columns) or transformations we want to understand. When we ask “what does this matrix do?”, we’re asking: how does it stretch, rotate, or compress what we put through it? Can we summarize that action simply?
For square matrices, eigenvalues and eigenvectors answer this beautifully. But most data matrices aren’t square. The question remains valid; the tool fails. SVD emerges as the natural replacement: instead of one set of special directions, we get two: one for the input space, one for the output, linked through singular values. This “find the essence” theme will reappear when we reformulate SVD variationally.
Linear Algebra Prerequisites
This post assumes familiarity with eigenvalues, eigenvectors, and matrix factorizations. If you need a refresher:
For intuition: Grant Sanderson’s Essence of Linear Algebra builds geometric understanding from first principles
For depth: Gilbert Strang’s MIT 18.06 Linear Algebra remains the gold standard for rigorous yet accessible treatment
Eigenvalues and Eigenvectors
For a square matrix, eigenvalues and eigenvectors capture its essence. An eigenvector \(v\) satisfies \(Av = \lambda v\): the matrix acts on it by pure scaling. The eigenvalue \(\lambda\) tells the story:
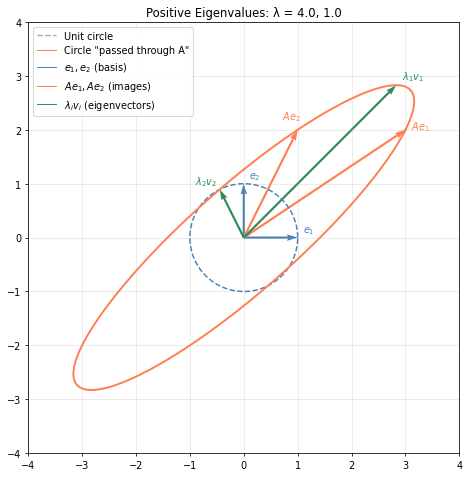
What does this matrix actually do? Each column of \(A\) tells us where a standard basis vector lands: \(e_1 = [1,0]\) maps to \(Ae_1 = [3,2]\), and \(e_2 = [0,1]\) maps to \(Ae_2 = [1,2]\). But this doesn’t reveal the structure.
To see the essence, pass a unit circle through \(A\). Every point on the circle is a unit vector; its image shows how \(A\) stretches and rotates space. The circle becomes an ellipse. The eigenvectors point in directions where \(A\) acts by pure scaling, with no rotation. Along \(v_1\), space stretches by \(\lambda_1 = 4\). Along \(v_2\), it stretches by \(\lambda_2 = 1\).
Are Eigenvectors perpendicular?
For general square matrices, eigenvectors aren’t necessarily perpendicular. The exception: symmetric matrices, whose eigenvectors are always orthogonal. Covariance matrices, which appear constantly in ML, are symmetric with non-negative eigenvalues making them positive semidefinite (positive definite when full rank).
Computing eigenvalues by hand means solving \(\det(A - \lambda I) = 0\), which gets tedious fast. In practice, we let NumPy handle it:
import numpy as npA = np.array([[3, 1], [2, 2]]) # Non-symmetric: eigenvectors won't be orthogonaleigenvalues, eigenvectors = np.linalg.eig(A)print(f"Eigenvalues: {eigenvalues}")print(f"Eigenvectors:\n{eigenvectors}")
This eigenvalue story is elegant for square matrices. But recall our opening question: most data matrices are rectangular: m samples as rows, n features as columns. When we ask “what does this matrix do?” for real data, we need an answer that works beyond the square case.
When Eigenvalues Fail
Now consider a 2×3 matrix (perhaps two measurements across three sensors, or two data points with three features):
Can we compute eigenvalues? The eigenvalue equation \(Av = \lambda v\) requires that \(v\) and \(Av\) live in the same space: we subtract them to get \((A - \lambda I)v = 0\). But here \(v \in \mathbb{R}^3\) and \(Av \in \mathbb{R}^2\). The dimensions don’t match. There is no identity matrix \(I\) that makes \(A - \lambda I\) meaningful.
Eigenvalues are fundamentally about a matrix acting on a space and returning to that same-dimensional space. Rectangular matrices map between spaces of different dimensions. We need a different tool.
The Four Subspaces of a Matrix
Quick dimension check
For a \(2 \times 3\) matrix \(A\), the input vector \(x\) must be in \(\mathbb{R}^3\) and the output \(Ax\) lands in \(\mathbb{R}^2\):
The “inner” dimensions must match (3 = 3), and the “outer” dimensions give the result shape.
Consider again our 2×3 matrix \(A\). It takes 3D vectors as input and produces 2D vectors as output. We’re squashing 3D down to 2D. Something must get lost.
Where do the inputs live?
Look at the rows of \(A\): they are two vectors in \(\mathbb{R}^3\):
Row 1: \((1, 2, 0)\)
Row 2: \((0, 1, 2)\)
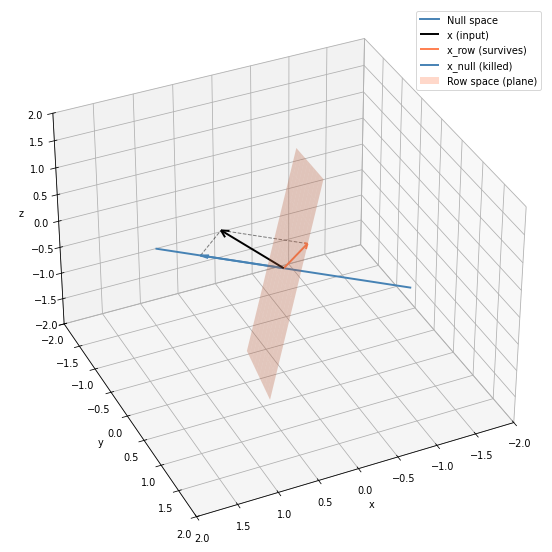
These two vectors span a plane in 3D. This plane is the row space as shown in Figure 1
Now imagine feeding a 3D vector \(x\) into \(A\). Three things can happen:
\(x\) lies in the row space plane: it maps to something nonzero in \(\mathbb{R}^2\)
\(x\) is perpendicular to that plane: it gets killed, \(Ax = 0\)
\(x\) is tilted away from the plane: it splits into two parts. The part in the plane survives; the part perpendicular to it vanishes (the situation we are portraying in Figure 1)
The perpendicular direction (and anything along it) is the null space.
The decomposition
As shown in Figure 1, any input vector \(x \in \mathbb{R}^3\) splits uniquely into two orthogonal pieces:
\[x = x_{\text{row}} + x_{\text{null}}\]
When \(A\) acts:
\(Ax_{\text{row}}\) → lands in the column space (nonzero)
\(Ax_{\text{null}}\) → vanishes to zero
So \(Ax = Ax_{\text{row}}\). The null space component is silently erased. Only the row space projection determines the output. This is why information is “lost” when we squash dimensions; vectors that differ only in their null space component become indistinguishable after multiplication.
Rank of a matrix
The dimension of the row space is called the rank of the matrix (here, rank 2). A fundamental theorem: row space and column space always share the same dimension. And notice: rank + dim(null space) = 3 (the input dimension). Our 2×3 matrix has rank 2, so the null space is 1 dimensional (exactly one direction gets erased).
Figure 1: Input space decomposition
The output side
We’ve seen two of the four subspaces: the row space (directions that survive) and the null space (directions that get killed). Both live in the input space \(\mathbb{R}^n\).
Now for the other two. Think of \(A\) as a linear map from \(\mathbb{R}^n\) to \(\mathbb{R}^m\). Its transpose \(A^T\) goes the other way: from \(\mathbb{R}^m\) back to \(\mathbb{R}^n\). The remaining two subspaces come from asking the same questions about \(A^T\) that we asked about \(A\):
Column space: where \(A\) can actually send vectors (the “row space” of \(A^T\))
Left null space: directions in the output that \(A\) can never reach (the “null space” of \(A^T\))
For our 2×3 matrix, the column space fills all of \(\mathbb{R}^2\), every output point is reachable. So there’s no left null space.
But imagine we had a 3×2 matrix instead (expanding 2D → 3D). Now the roles flip: - Every input direction is used (no null space) - The matrix maps all of \(\mathbb{R}^2\) to a plane in \(\mathbb{R}^3\) (still rank 2), but not every vector in \(\mathbb{R}^3\) is reachable, the direction perpendicular to this plane is the left null space
The symmetry: what the null space is to \(A\), the left null space is to \(A^T\).
The Four Fundamental Subspaces: A Summary
Space
Lives in
What it represents
Row space
Input \(\mathbb{R}^n\)
Directions that produce output
Null space
Input \(\mathbb{R}^n\)
Directions that get killed
Column space
Output \(\mathbb{R}^m\)
Where outputs land
Left null space
Output \(\mathbb{R}^m\)
Directions never reached
The matrix creates a perfect one-to-one map between row space and column space. The null spaces are the “leftovers”, killed on input, unreachable on output.
Finding the Four Subspaces
We’ve seen the geometry: four subspaces, with \(A\) creating a perfect map between row space and column space. But how do we actually find orthonormal bases for these subspaces?
The trick: form two square, symmetric matrices:
\(A^TA\) (lives in input space \(\mathbb{R}^n\)) captures how columns correlate
\(AA^T\) (lives in output space \(\mathbb{R}^m\)) captures how rows correlate
Both are symmetric, so they have orthogonal eigenvectors. And the beautiful fact: these eigenvectors partition exactly into our four subspaces.
Matrix
Eigenvectors with \(\lambda > 0\)
Eigenvectors with \(\lambda = 0\)
\(A^TA\)
Row space
Null space
\(AA^T\)
Column space
Left null space
Let’s verify this connection numerically. We’ll compute the eigendecompositions of \(A^TA\) and \(AA^T\), then compare their eigenvectors with what SVD produces directly:
# Eigendecompositionseig_vals_ATA, eig_vecs_ATA = np.linalg.eig(A.T @ A)eig_vals_AAT, eig_vecs_AAT = np.linalg.eig(A @ A.T)# Sort by eigenvalues (descending) to match SVD orderingidx_ATA = np.argsort(eig_vals_ATA)[::-1]idx_AAT = np.argsort(eig_vals_AAT)[::-1]V_from_eig = eig_vecs_ATA[:, idx_ATA]U_from_eig = eig_vecs_AAT[:, idx_AAT]sigma_sq = np.sort(eig_vals_ATA)[::-1][:2] # nonzero eigenvalues# Compare with SVDU, sigma, Vt = np.linalg.svd(A)print("Eigenvalues (σ²):", sigma_sq)print("Singular values squared:", sigma**2)print("\nU matches (up to sign)?", np.allclose(np.abs(U_from_eig), np.abs(U)))print("V matches (up to sign)?", np.allclose(np.abs(V_from_eig), np.abs(Vt.T)))
Eigenvalues (σ²): [7. 3.]
Singular values squared: [7. 3.]
U matches (up to sign)? True
V matches (up to sign)? True
Why does this work?
The null space connection: If \(v\) is in the null space, then \(Av = 0\), so \(A^TAv = 0\), meaning \(v\) is an eigenvector of \(A^TA\) with eigenvalue zero.
The row space connection: Symmetric matrices have orthogonal eigenvectors (see Strang’s course, or verify numerically). Since \(A^TA\) is \(n \times n\) and symmetric, its eigenvectors form an orthonormal basis for all of \(\mathbb{R}^n\). We just showed the null space eigenvectors have \(\lambda = 0\). The remaining eigenvectors (with \(\lambda > 0\)) must be orthogonal to them. But we also know the row space and null space are orthogonal complements in \(\mathbb{R}^n\). So these remaining eigenvectors span exactly the row space.
The same logic applies to \(AA^T\) on the output side: zero eigenvalue eigenvectors give the left null space, and the rest give the column space.
This is geometric intuition, not a formal proof, but it shows why the eigendecompositions naturally reveal our four subspaces.
SVD: Finding structure in both spaces
We already computed the SVD above when verifying the eigendecomposition connection. Let’s examine what it returned: orthonormal bases for the input and output spaces, linked through the singular values.
The SVD returns two singular values: \(\sigma_1 \approx 2.65\) and \(\sigma_2 \approx 1.73\). Why only two? For an \(m \times n\) matrix, you get at most \(\min(m, n)\) nonzero singular values (here, \(\min(2, 3) = 2\)). Since both rows of \(A\) are linearly independent (rank 2), we get exactly two positive values. The “missing” third direction in \(\mathbb{R}^3\) is the null space; it gets killed by \(A\), contributing nothing to the output. The matrices \(U\) and \(V\) contain orthonormal vectors: U.T @ U and Vt @ Vt.T both yield the identity matrix, confirming that the singular vectors form orthonormal bases for the column space and row space respectively.
print("V^T @ V (should be I):\n", np.round(Vt @ Vt.T, 10))print("\nU^T @ U (should be I):\n", np.round(U.T @ U, 10))
V^T @ V (should be I):
[[ 1. -0. 0.]
[-0. 1. 0.]
[ 0. 0. 1.]]
U^T @ U (should be I):
[[ 1. -0.]
[-0. 1.]]
The geometry of SVD
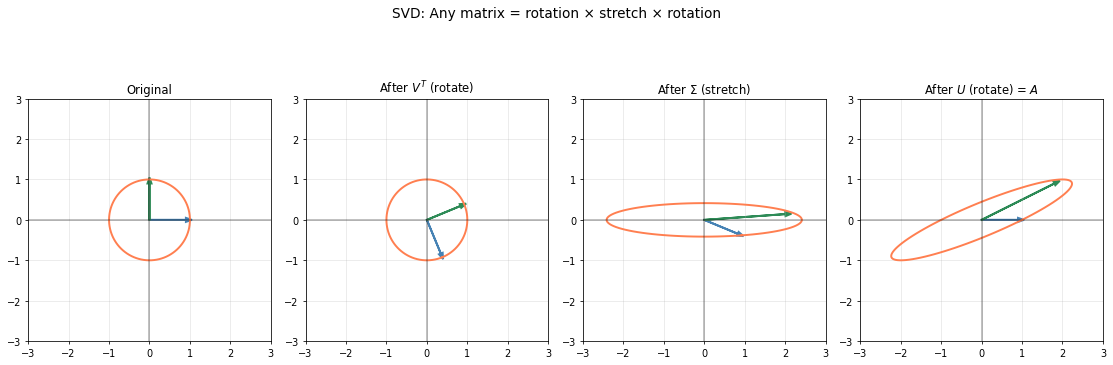
The SVD reveals that any matrix can be decomposed into three simple operations:
Pass a unit circle through each step and watch it transform into an ellipse.
Note: We use a 2×2 matrix here for visualization clarity. With our 2×3 example, the input space is 3D (making the “rotate → stretch → rotate” harder to show in 2D plots). The geometric principle is identical: SVD always decomposes a linear map into rotations and axis-aligned stretching, but square matrices let us see all three steps in the same plane.
What SVD Reveals
We’ve seen that SVD decomposes any matrix into rotations and axis-aligned stretching. The singular values tell us how much the matrix stretches along each principal direction. Looking at the ellipse, the longest axis has length \(\sigma_1\), the largest singular value.
This suggests a natural question: can we characterize \(\sigma_1\) directly as an optimization problem? Among all unit vectors \(v\), which one gets stretched the most by \(A\), and by how much?
This viewpoint (finding special directions through optimization) leads to a variational formulation of SVD with a rich history (see Stewart’s 1993 overview for early contributions). We’ll derive SVD through this classical variational principle in the remainder of this post. In Parts 2 and 3, we’ll see how Suykens’ LS-SVM reformulation opens the door to kernel extensions and, ultimately, connections to attention mechanisms in transformers.
The Variational Perspective
Variational Principle
A variational Principle reformulates a problem as: “find the object that maximizes (or minimizes) some quantity.” Instead of solving equations directly, we search for extrema. This often reveals structure and enables new solution methods.
The Classical Variational Problem
SVD asks: which directions in input and output space are most strongly coupled through the matrix? We measure coupling strength with the bilinear form:
\[f(u, v) = u^T A v\]
where \(u \in \mathbb{R}^m\) lives in output space and \(v \in \mathbb{R}^n\) lives in input space.
Why “bilinear”? The function is linear in each argument separately: if you fix \(v\) and vary \(u\), you get a linear function of \(u\); fix \(u\) and vary \(v\), linear in \(v\). But it’s not linear in both together: scaling both by 2 multiplies the output by 4, not 2.
Reading the bilinear form geometrically
The expression \(u^T A v\) has a natural interpretation: take a unit vector \(v\) from input space, pass it through \(A\) to get \(Av\) in output space, then measure how aligned this output is with \(u\) via the dot product \(u^T(Av)\). Maximizing over both \(u\) and \(v\) means: find the input direction that, when transformed by \(A\), can be most strongly aligned with some output direction.
This connects to our earlier “maximum stretch” picture. When \(u\) perfectly aligns with \(Av\), the dot product equals \(\|Av\|\) (since \(\|u\|=1\)). So maximizing coupling is finding maximum stretch, but now framed as a relationship between two spaces rather than a property of one.
Why Constrain the Norms?
Without constraints, maximizing \(u^T A v\) is trivial: just scale \(u\) and \(v\) to infinity. The coupling grows without bound, telling us nothing about the matrix’s structure.
Fixing \(\|u\| = \|v\| = 1\) removes this scaling freedom. Now we’re asking a meaningful geometric question: among all unit vectors, which pair aligns most strongly through \(A\)? And what is this maximum value? We’ll find out by solving the constrained optimization problem.
Making it concrete
Let’s see this variational formulation in action. We have our SVD of the 2×3 matrix \(A\): the right singular vectors \(v_1, v_2\) span the row space (a 2D plane in \(\mathbb{R}^3\)).
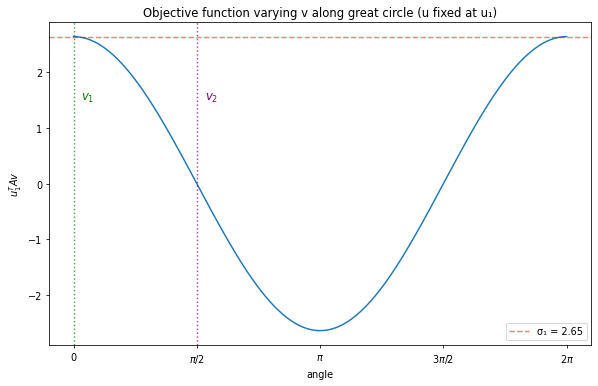
Fix \(u = u_1\) and parameterize \(v = \cos(t) \cdot v_1 + \sin(t) \cdot v_2\). This traces a unit circle in that plane. At \(t=0\) we’re at \(v_1\); at \(t=\pi/2\) we’re at \(v_2\). What does the objective \(u_1^T A v\) look like as we walk around this circle?
A = np.array([[1, 2, 0], [0, 1, 2]])U, sigma, Vt = np.linalg.svd(A)# Extract singular vectorsv1, v2 = Vt[0], Vt[1] # rows of Vt are the right singular vectorsu1, u2 = U[:, 0], U[:, 1]# Parameterize great circle through v1 and v2t = np.linspace(0, 2*np.pi, 200)v_circle = np.array([np.cos(t_i) * v1 + np.sin(t_i) * v2 for t_i in t])# Compute objective along this circleobjective = [u1 @ A @ v for v in v_circle]fig, ax = plt.subplots(figsize=(10, 6))ax.plot(t, objective)ax.set_xlabel('angle'); ax.set_ylabel(r'$u_1^T A v$')ax.axhline(sigma[0], color='r', linestyle='--', alpha=0.5, label=f'σ₁ = {sigma[0]:.2f}')ax.axvline(0, color='green', linestyle=':', alpha=0.7)ax.axvline(np.pi/2, color='purple', linestyle=':', alpha=0.7)ax.text(0.1, 1.5, r'$v_1$', color='green', fontsize=12)ax.text(np.pi/2+0.1, 1.5, r'$v_2$', color='purple', fontsize=12)ax.set_xticks([0, np.pi/2, np.pi, 3*np.pi/2, 2*np.pi])ax.set_xticklabels(['0', r'$\pi/2$', r'$\pi$', r'$3\pi/2$', r'$2\pi$'])ax.legend()ax.set_title('Objective function varying v along great circle (u fixed at u₁)')plt.show()
At \(v_1\), the objective reaches its maximum \(\sigma_1 = 2.65\). The curve looks smooth and convex around this point. But wait: we also see a minimum at \(t=\pi\) (which is just \(-v_1\), giving \(-\sigma_1\)). And the curve passes through zero at \(v_2\).
This hints at something important: we’re not looking at a single global optimum, but at multiple stationary points. The landscape has both maxima and minima. Why?”
Why Multiple Solutions?
In convex optimization, life is simple: a bowl has one bottom, and gradient descent finds it. But our problem is doubly non-convex:
The constraints aren’t convex: The unit sphere \(\|u\| = 1\) isn’t a convex set. Pick any two points on a circle and draw the line segment between them, it passes through the interior, not along the circle. A convex set must contain all such segments.
The objective isn’t convex: The bilinear form \(u^T A v\) curves upward in some directions and downward in others (a saddle, not a bowl).
So we won’t find the optimum. Instead, we find all stationary points of the Lagrangian. The beautiful result: these stationary points are exactly the singular vector pairs \((u_i, v_i)\), with stationary values \(\pm \sigma_i\). SVD emerges from solving for every extremum, not just one.
Why isn’t the bilinear form convex?
Consider the simplest bilinear form: \(f(x, y) = xy\). To check convexity, we compute the Hessian (matrix of second derivatives):
From \(\lambda_1 + \lambda_2 = 0\) we get \(\lambda_2 = -\lambda_1\). Substituting into \(\lambda_1 \lambda_2 = -1\) gives \(-\lambda_1^2 = -1\), so \(\lambda_1 = \pm 1\). The eigenvalues are \(\lambda = +1\) and \(\lambda = -1\).
One positive, one negative: the Hessian is indefinite. This means \(f(x,y) = xy\) is a saddle surface: curving upward in some directions, downward in others. Not convex, not concave.
Intuition: \(v^T H v\) gives the curvature (second derivative) in direction \(v\). Positive definite means positive curvature in every direction (a bowl). Indefinite means some directions curve up, others down (a saddle).
The general bilinear form \(u^T A v\) inherits this structure. No matter what \(A\) is, mixing input and output variables creates saddle geometry.
Constrained Optimization Prerequisites
We’ll use Lagrange multipliers to solve constrained optimization. The core idea: move constraints into the objective function as penalty terms. Each constraint gets a multiplier representing the “price” for violating it. This converts a constrained problem into an unconstrained one we can solve with calculus.
If you need a refresher:
For intuition: The Visually Explained series builds geometric understanding of convex optimization, Lagrangians, and KKT conditions (Karush-Kuhn-Tucker: taking the partial derivatives of the Lagrangian and setting them to zero)
For depth: Boyd & Vandenberghe’s Convex Optimization is the standard reference (free PDF available, and Boyd’s Stanford lectures are online)
Derivatives with Respect to Vectors
The Lagrangian derivation requires differentiating with respect to vectors \(u\) and \(v\). If this is unfamiliar, Chieh Wu’s Derivatives with Respect to Vectors provides a clear introduction.
For brevity here: think of \(\|u\|^2 = u^T u\) as analogous to \(x^2\) in single variable calculus, and \(u^T A v\) as analogous to \(xy\). The derivative of \(x^2\) is \(2x\); the derivative of \(\|u\|^2\) with respect to \(u\) is \(2u\). Similarly, \(\frac{\partial}{\partial u}(u^T A v) = Av\) (treating \(v\) as constant). The rules follow the same intuition as polynomials of degree 2.
The Lagrangian Derivation
We want to find stationary points of:
\[\max_{u, v} \; u^T A v \quad \text{subject to} \quad \|u\|^2 = 1, \; \|v\|^2 = 1\]
Introduce multipliers \(\lambda\) and \(\mu\) for the two constraints:
\[\mathcal{L}(u, v, \lambda, \mu) = u^T A v - \frac{\lambda}{2}(\|u\|^2 - 1) - \frac{\mu}{2}(\|v\|^2 - 1)\]
Differentiate and set to zero:
\[\frac{\partial \mathcal{L}}{\partial u} = Av - \lambda u = 0 \quad \Rightarrow \quad Av = \lambda u\]
\[\frac{\partial \mathcal{L}}{\partial v} = A^T u - \mu v = 0 \quad \Rightarrow \quad A^T u = \mu v\]
Multiply the first equation by \(u^T\): we get \(u^T A v = \lambda\) (using \(\|u\|^2 = 1\)).
Multiply the second by \(v^T\): we get \(v^T A^T u = \mu\).
But \(v^T A^T u = (u^T A v)^T = u^T A v\), so \(\lambda = \mu\).
The Shifted Eigenvalue Problem
With \(\lambda = \mu\), stack the two conditions into a block matrix:
\[\begin{bmatrix} 0 & A \\ A^T & 0 \end{bmatrix} \begin{bmatrix} u \\ v \end{bmatrix} = \lambda \begin{bmatrix} u \\ v \end{bmatrix}\]
Why “shifted”? The diagonal blocks are zero: all the coupling lives in the off-diagonal blocks \(A\) and \(A^T\). The eigenvalues of this block matrix are exactly \(\pm \sigma_1, \pm \sigma_2, \ldots, \pm \sigma_r\) (plus zeros if the matrix is rectangular), where \(\sigma_i\) are the singular values of \(A\).
Recovering the SVD
From the shifted eigenvalue problem, we get \(r\) pairs of eigenvectors \((u_i, v_i)\) with eigenvalues \(\pm \sigma_i\). Stack the \(u_i\) as columns of \(U\), the \(v_i\) as columns of \(V\), and place \(\sigma_i\) on the diagonal of \(\Sigma\).
The stationarity conditions \(Av_i = \sigma_i u_i\) become:
\[AV = U\Sigma\]
Multiply on the right by \(V^T\):
\[A = U \Sigma V^T\]
The variational principle didn’t just find singular vectors, it derived the entire factorization from “find maximally coupled directions”.
Let’s verify this: the eigenvalues of the block matrix should be exactly \(\pm\sigma_i\) (plus a zero from the null space):
# Build the shifted block matrixm, n = A.shapeblock = np.block([[np.zeros((m, m)), A], [A.T, np.zeros((n, n))]])# Its eigenvalues should be ±σ and zeroseigs = np.linalg.eigvalsh(block)print("Block matrix eigenvalues:", np.sort(eigs)[::-1])print("Singular values:", sigma)
The eigenvalues come in pairs \(\pm\sigma_i\), confirming the theory. The value near \(10^{-15}\) is numerically zero. This corresponds to the null space direction (our matrix has rank 2, but the block matrix is 5×5, so one eigenvalue must be zero).
This classical variational formulation isn’t how we compute SVD in practice (numerical libraries handle that efficiently). But understanding the variational view opens a door to something deeper.
What if we could replace the hard constraints \(\|u\|^2 = 1\) and \(\|v\|^2 = 1\) with something more flexible? Instead of forcing unit norm, imagine two opposing forces: one rewards capturing variance through projections, while the other charges a price for making \(w\) large. Want to maximize variance? Sure, but growing \(w\) costs you.
Next: The LS-SVM Reformulation
In Part 2, we take a detour through PCA to build intuition for this new perspective. Johan Suykens’ LS-SVM framework replaces hard constraints with competing forces: variance versus regularization. The result? Equilibrium points that emerge at special “quantized” values of the regularization parameter, corresponding exactly to the principal components.
This isn’t about maximizing or minimizing. It’s about finding balance. And the geometry is beautiful: ridges, thalwegs, and polar landscapes that reveal the structure hidden in your data.
Once we’ve internalized this for PCA, we’ll be ready for Part 3: SVD revisited, where two data sources, asymmetric kernels, and the connection to attention mechanisms await.